

はじめに ~連載について~
サステナビリティは、いまや材料開発の前提条件となりました。
性能と環境負荷を両立する「選ばれる素材」をどう設計するか。
本連載では、「サステナブル時代の『選ばれる素材』開発ロードマップ~CrowdChemの300万件データと現場を繋ぎ、次世代R&Dの『最適解』を導き出す~」を主テーマに、全10回にわたり、弊社の取り組みや知見も交えながらご紹介していきます。
全10回タイトル:サステナブル時代の「選ばれる素材」開発ロードマップ
~CrowdChemの300万件データと現場を繋ぎ、次世代R&Dの「最適解」を導き出す~
なお、本記事は、全10回の連載のうち、第2回の記事となります。
第1回コラムでは、カーボンニュートラルに向けた「2031年の壁」―欧州ELV規則案による再生材25%活用の義務化―が、樹脂産業にいかに破壊的な変化を迫っているかについて解説しました。
この難題を前に、多くの化学・素材メーカーが「DX&IT変革」として推進しているのがMI、PIではないでしょうか。データとAIの力で開発を加速する―その可能性に大きな期待が寄せられています。
しかし、現実はどうでしょうか? 実際、あなたの会社でこんな声を聞いたことはありませんか?
「数千万円かけてMIツールを導入したが、結局ベテラン技術者の勘が当たっている」
「AIの予測が現場の感覚と乖離しており、使われなくなった」
「予測するためのデータ量が少ないため、実態と合わない結果になった」
なぜ、革新的開発手法であるはずのMI、PIが現場で浸透しないのでしょうか。その背景や謎を紐解きながら「300万件のグラフ構造化データ」がいかにしてその壁を打ち破るのかをご説明します。
「データの量」と「質の不備」―MI、PIが挫折する真の理由とは?
新機能・高機能材料による市場確保は、企業にとって最大の「成長機会」です。
下図は、日本の化学企業が持つ機能材料の市場ポジションを示したものです(データは令和2年度時の資料)。機能性材料は、自動車や医療産業よりは規模は小さいですが、市場シェア50%以上を獲得している状況です。
このように日本企業は新機能・高機能材料開発を得意分野としています。
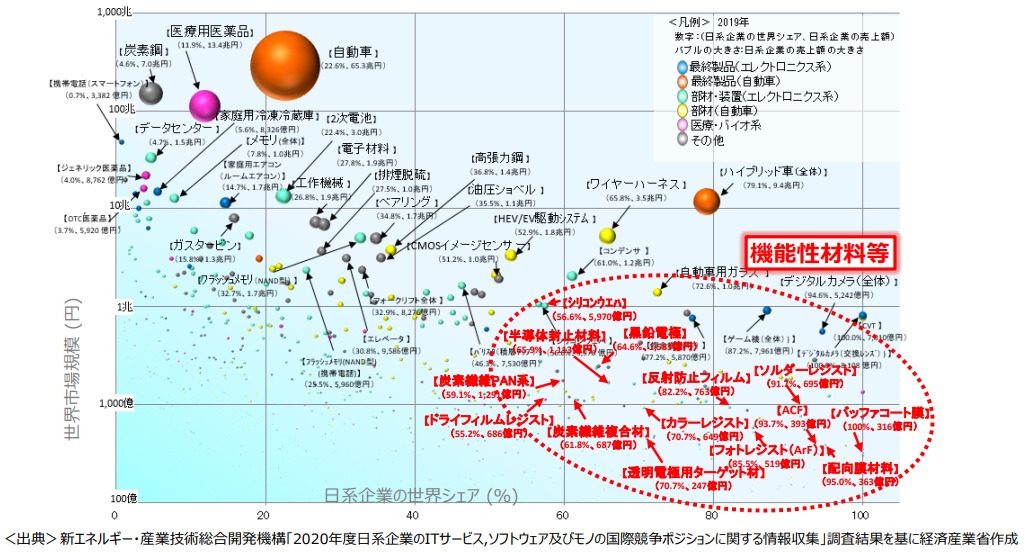
一方、この強みを維持するための代償も大きくなっています。研究開発の長期化とコスト高という深刻な「リスク」です。
これまでは顕在化していなかったリスクですが、時代の流れが急速に変化している今、徐々に顕在化しつつあります。市場に関しても当然ながら、いつまでもこのシェアを獲得できるとは限りません。各企業は、更なる開発速度の促進と人件費削減というトレードオフの状態になっている中でMI、PIの導入を推進しているところです。
では、なぜ期待のMI、PIが現場で機能しないのでしょうか。多くの企業で共通して聞かれる失敗の原因は、主に次の2つに集約されるのではないでしょうか。
1つ目は、「圧倒的な学習データの不足」です。
一般的なMI、PIツールは、顧客が自社で保有する過去の実験データのみを学習対象とします。しかし、一企業が特定のテーマで保有する良質なデータは、多くても数百から数千件程度。AIが真に「化学的な真理」を理解するには、その規模では不十分です。
2つ目は、「データの扱いやすさ」の問題です。
AIが処理できるのは、整理整頓された「構造化データ」だけです。しかし、実際、開発現場にある情報の多くは、個人の実験ノートや、人によって書式がバラバラなExcelファイル、あるいはPDF化された論文などの「非構造化データ」の状態です。この「非構造化データ」を活かすことができないことが、MI、PI導入を阻むボトルネックではないでしょうか。
属人化する「匠の技」と、埋もれる「失敗の記録」
MI、PIが進まない根底のひとつにあるのは、皮肉にも日本のモノづくりを支えてきた「属人化」ではないでしょうか。
これまでの材料開発は、熟練研究者の「勘と経験」に依存してきました。実験の細かなニュアンス、温度の設定根拠等のプロセス情報は、研究者の頭の中にだけ存在し、組織として共有されることは稀でした。
そして、成功データのみを蓄積して、失敗データの埋没という状況に陥るのではないでしょうか。具体的には、成功した結果は報告書や設計図などに残ることが多いですが、その過程で生まれた数多くの失敗データは残ることはありません。そして多くの人はその失敗過程を知ることはないでしょう。
しかし、AIにとっては何が失敗だったのかというデータこそが予測精度を高めることができる貴重なデータなのです。そして成功データの蓄積量では圧倒的に情報量が少ないという状況になり、これはMI、PI設計者の悩みの種になるのではないでしょうか。
また、新機能・高機能材料を開発するにあたり、成功情報のみではデータ量だけなく、過学習に近い状態になることから、根拠の明確さにも欠ける可能性もあります。設計者は、データ量と根拠の明確化を確立しながらMI、PIに向き合っていくことが必要になるのではないでしょうか。
300万件を「グラフ構造化」し、世界初の「グラフ構造AI」で解き明かす
では、この状況を打開するにはどうすればよいのでしょうか。私達は、この「データ不足」と「根拠の明確化」を根本から解決するソリューションを構築しました。そのソリューションの二つの柱をご紹介します。
第一の柱は、300万件超の「グラフ構造化データ」という圧倒的な基盤です。
具体的には、世界中の特許、論文、製品カタログから抽出した300万件以上の化学データを独自に保有しています。独自の自然言語処理技術(NLP)により、本来は読み解くのが困難な「非構造化データ」をAIが即座に学習できる「グラフ構造化データ」へと変換することを可能としています。自社のデータが少なくても、この膨大な外部知見をベースモデルとして活用することで、開発をゼロからではなく「ゴール付近」からスタートさせることが可能になります。
第二の柱は、世界初のプロセスを理解する「グラフ学習AIモデル」(特許取得済)です。従来のAIの多くは、Excelのような「表形式(Table)」のデータを学習する方式でした。しかし、化学は「何を混ぜたか(成分)」と同じくらい「どう作ったか(工程)」が重要です。 私達が構築した「グラフ学習AIモデル」は、原料や量だけでなく、製造プロセス(混合、温度、圧力等)を「ノード(点)」と「エッジ(線)」で繋いだ「グラフ構造」として学習します。これにより、成分(MI)と工程(PI)を切り離すことなく、一気通貫で最終物性との因果関係を解き明かすことができるのです。
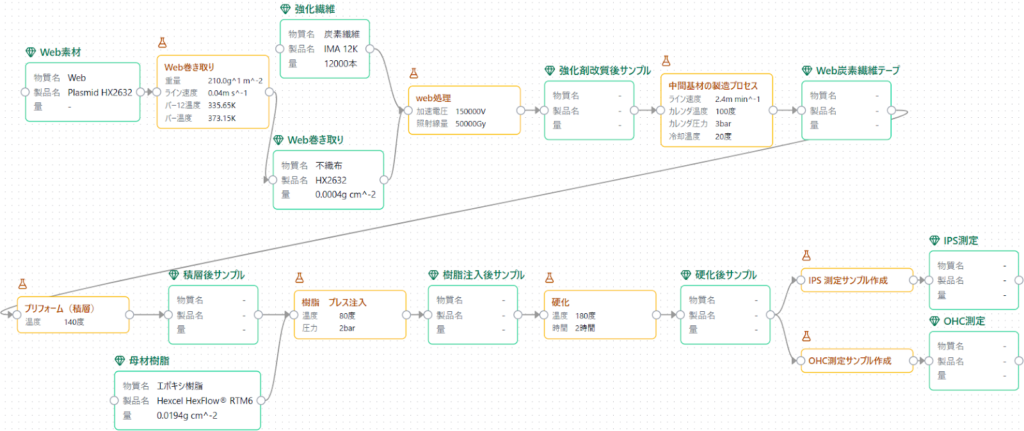
特許を事例として、グラフ構造化データの一例を示します。上図は、特表2021-504513の実施例の一つである、ウェブ素材を用いて強度を改善したエポキシ樹脂の製造例を示しています。
特許に記載の製造方法を読み解き、配合の開始から、ターゲット物性である開口圧縮強度(OHC)および面内剪断(IPS)応力の測定までをグラフ構造化しています。
これはまさに文字で整理された「非構造化データ」です。このような情報を整理することはそもそも膨大な時間がかかります。またエクセルなどで体系的に整理できたとしてもそれをどのような形で活用するのかも難しいのではないでしょうか。
エクセル上でMIやPI反応を行うことはできるかもしれませんが、簡単な作業ではありません。私達のグラフ学習AIモデルはその悩みを一気に解消することができます。
グラフ構造AIモデルだけでない私たちの強み
今回はグラフ学習AIモデルの強みについて一部ご紹介しました。私達の強みはこれだけではありません。実験工程のデータ化、実験データの閲覧・管理、お客様保有データの追加学習、要因分析、機械学習による予測結果などデータベースの枠を大きく超えた次世代インフラ「LabDX」を所有しております。
このLabDXがお客様の何を解決していくのか?については、次回以降のコラムにてご紹介したいと思いますので、ぜひご期待ください。
貴社の「眠れるデータ」を、明日を創る武器へ
改めて整理しましょう。MI、PIは、単なるソフトウェアではありません。散逸した「非構造化データ」を整理し、組織の「共有知」へと昇華させるためのインフラ(基盤)です。繰り返しになりますが、時間は待ってくれません。
自動車産業で言えば、2031年の環境規制施行まで、残された時間はほとんどありません。「自社データだけで何とかしよう」という従来のこだわりを捨て、私達が持つ300万件のデータと学習グラフAIという「最新の武器」を手に開発の「最短航路」を走り出しませんか。
まずは、今抱えている「材料開発のボトルネック」をお聞かせください。
第3回:化審法規制と再生材活用を阻む「見えないリスク」の回避
近年、PFASなどの化学物質に関する規制が強化されていることはご存じかと思います。持続可能な社会を継続する上では環境負荷物質の規制は今後ますます厳しくなると推測されます。あなたが当たり前のように扱っていた化学物質も明日には使えなくなる?そんな日も到来する可能性があります。そして近年の再生材利用における材料開発における見えない罠も・・・








